Recently, I’ve come across a not so efficient implementation of a isEven function (from r/programminghorror).
bool isEven(int number)
{
int numberCompare = 0;
bool even = true;
while (number != numberCompare)
{
even = !even;
numberCompare++;
}
return even;
}
The code is in C++, but the essence of the algorithm is an iterative ascent to the input number from base case 0 (which is even), switching the boolean result at each iteration. It works, but you get a linear time \(O(n)\) isEven function compared to the obvious constant time \(O(1)\) modulo algorithm.
Surprisingly, Clang/LLVM is able to optimize the iterative algorithm down to the constant time algorithm (GCC fails on this one). In Clang 10 with full optimizations, this code compiles down to:
; Function Attrs: norecurse nounwind readnone ssp uwtable
define zeroext i1 @_Z6isEveni(i32 %0) local_unnamed_addr #0 {
%2 = and i32 %0, 1
%3 = icmp eq i32 %2, 0
ret i1 %3
}
The first instruction is a boolean AND with 1 to keep only the least significant bit (a very fast way to compute a modulo %2), and the second instruction compares the result with 0.

I’ve decided to explore how Clang was able to do this. As you may know, an optimizer like LLVM (Clang backend) is designed with a bunch of specific passes which transform the code (in the form of LLVM IR) into another (preferably more optimized) code, keeping the same semantic. LLVM has a around 50 different optimization passes, each one targets a specific code pattern.
When you give a specific optimization level to your compiler (such as -O2), there is a fixed list of optimization passes which will be executed on your code to optimize it (the list has already been defined for you by the compiler writers)1.
Original code
Clang compiles the C++ isEven function to straightforward assembly (in the form of LLVM IR) if you don’t apply any optimization passes (-O0).
; Function Attrs: noinline nounwind ssp uwtable
define zeroext i1 @_Z6isEveni(i32 %0) #0 {
%2 = alloca i32, align 4 ; number
%3 = alloca i32, align 4 ; numberCompare
%4 = alloca i8, align 1 ; even
store i32 %0, i32* %2, align 4 ; store function argument in number
store i32 0, i32* %3, align 4 ; store 0 in numberCompare
store i8 1, i8* %4, align 1 ; store 1 (true) in even
br label %5
5: ; preds = %9, %1
%6 = load i32, i32* %2, align 4
%7 = load i32, i32* %3, align 4
%8 = icmp ne i32 %6, %7
br i1 %8, label %9, label %16
9: ; preds = %5
%10 = load i8, i8* %4, align 1
%11 = trunc i8 %10 to i1
%12 = xor i1 %11, true
%13 = zext i1 %12 to i8
store i8 %13, i8* %4, align 1
%14 = load i32, i32* %3, align 4
%15 = add nsw i32 %14, 1
store i32 %15, i32* %3, align 4
br label %5
16: ; preds = %5
%17 = load i8, i8* %4, align 1
%18 = trunc i8 %17 to i1
ret i1 %18
}
LLVM IR is a form of low-level (close to the machine) intermediate representation, with the particularity of being in Single Static Assignment form (SSA). Each instruction is always producing a new value (looking like %3), and not reassigning a previous one.
A graphical version of the same IR is called a Control Flow Graph (CFG), it is a graph between vertices called basic block (sequence of instructions which are always executed entirely from top to bottom) and edges which represent a possible flow for our program. For our code, the CFG looks like this:
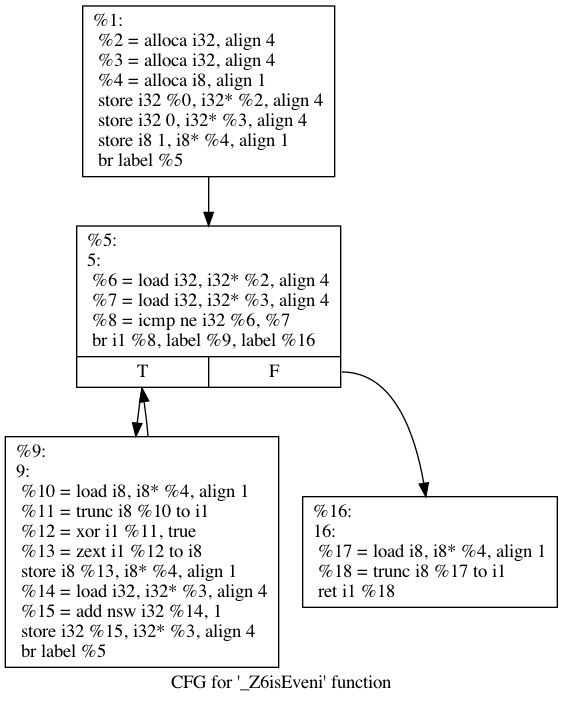
- The first block (numeroted
%1) initializes the memory for the various variables inside the function (two 4-bytes integers for number and numberCompare, one byte for even). - The second block (numeroted
%5) is the loop check to determine whether we should go inside the loop or exit it. - The third block (numeroted
%9) is the loop body, it increments numberCompare (%15) and toggles the boolean even (%12). - The fourth block is the return of the function, it converts the result to a boolean value (
%18) and returns it to the caller.
Optimizing the code
At this point, the code is simply an assembly SSA version of our original C++ code. Let’s run some LLVM optimization passes on it to see how it evolves.
Memory to register
The first pass we run is called Memory to Register (mem2reg): its goal is to move variables from memory (in RAM) to abstract registers2 (directly inside the CPU) to make it way faster (memory latency is ~100ns).
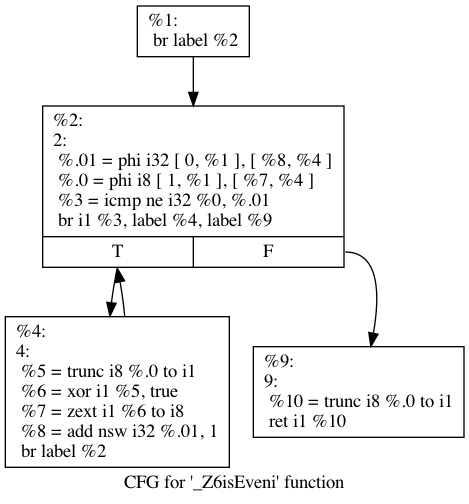
We see that all the instructions related to memory (alloca, load, store) have been removed by the optimizer and now all operations (add, xor) are done directly on CPU registers.
The 4 blocks are still there, but slightly different (they are looking way closer to the original C++ code):
- the initialization block is now empty.
- the loop condition block has changed, it contains 2 instructions called
phinodes. Those are special nodes which take a value out of 2 depending on the previously executed block (called the predecessor block).
For example, the line%.01 = phi i32 [ 0, %1 ], [ %8, %4 ]means that the variable%.01%(which represents numberCompare in our C++ code) should take either the value 0 if we come from the basic block%1which is the beginning of the function, or the value of%8if we come from the basic block%4which is the body of the loop.
Instruction combine
This pass combines several instructions into a simpler/faster one, for example, 2 consecutive additions on the same variable can be reduced to a single one ; or a multiply by 8 can be changed to a left shift by 3, etc…
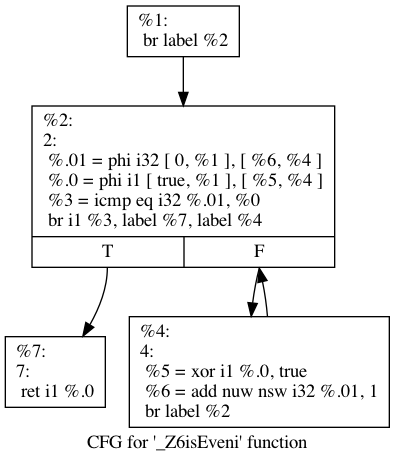
On our code, several changes has been made by this pass:
- even is no longer a byte (
i8) but stored directly as a single bit (i1), thus removing several conversion instructions. - the loop condition has been switch from a not equal to an equal, and the 2 blocs adapted to keep the semantic intact.
Loop and Induction variables
The next pass we will apply is the Canonicalize Induction Variables pass. This is the “magical” pass which completely removes our loop and thus turns the algorithm into constant time. The LLVM documentation explains:
Any use outside of the loop of an expression derived from the indvar is changed to compute the derived value outside of the loop, eliminating the dependence on the exit value of the induction variable. If the only purpose of the loop is to compute the exit value of some derived expression, this transformation will make the loop dead.
An induction variable (indvar) is the “counter” of a loop : sometimes the count is trivial such as for (i=0; i < 100; i++), the induction variable is i and trip count is 100 ; but often it is harder for the pass to determine the induction variable and loop trip count correctly. In our case, the induction variable numberCompare is obvious and the loop count number also.
Because it now only operates on a single bit value (thus having a maximum of 1), LLVM realizes here that our algorithm is a direct mathematical function of the loop count number and of the initial value:
\[even = ((initial \underbrace{* -1) * -1) *.... * -1}_{number} = initial * (-1)^{number}\]The CFG is now :
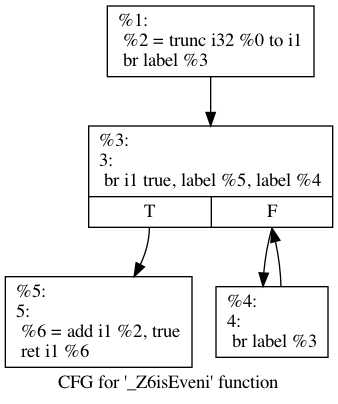
We run the pass -simplifycfg on the previous code, to remove any useless branching.
After a final instruction combine pass, we obtain the fully optimized \(O(1)\) complexity code.
; Function Attrs: noinline nounwind ssp uwtable
define zeroext i1 @_Z6isEveni(i32 %0) #0 {
%2 = trunc i32 %0 to i1
%3 = add i1 %2, true
ret i1 %3
}
Recursive version
Clang is also able to constantize the recursive linear time version of this algorithm! Finding the various optimization passes to produce the end result is left as an exercise to the reader 👨🏫.
bool isEvenRec(int number)
{
if (number == 0) return true;
return !isEvenRec(number-1);
}
Notes
-
This is the list of optimization passes (the order matters) that LLVM applies with flag -O2. Note that some of them are run multiple times :
-targetlibinfo -tti -targetpassconfig -tbaa -scoped-noalias -assumption-cache-tracker -profile-summary-info -forceattrs -inferattrs -ipsccp -called-value-propagation -attributor -globalopt -domtree -mem2reg -deadargelim -domtree -basicaa -aa -loops -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -instcombine -simplifycfg -basiccg -globals-aa -prune-eh -inline -functionattrs -domtree -sroa -basicaa -aa -memoryssa -early-cse-memssa -speculative-execution -aa -lazy-value-info -jump-threading -correlated-propagation -simplifycfg -domtree -basicaa -aa -loops -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -instcombine -libcalls-shrinkwrap -loops -branch-prob -block-freq -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -pgo-memop-opt -basicaa -aa -loops -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -tailcallelim -simplifycfg -reassociate -domtree -loops -loop-simplify -lcssa-verification -lcssa -basicaa -aa -scalar-evolution -loop-rotate -memoryssa -licm -loop-unswitch -simplifycfg -domtree -basicaa -aa -loops -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -instcombine -loop-simplify -lcssa-verification -lcssa -scalar-evolution -indvars -loop-idiom -loop-deletion -loop-unroll -mldst-motion -phi-values -aa -memdep -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -gvn -phi-values -basicaa -aa -memdep -memcpyopt -sccp -demanded-bits -bdce -aa -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -instcombine -lazy-value-info -jump-threading -correlated-propagation -basicaa -aa -phi-values -memdep -dse -aa -memoryssa -loops -loop-simplify -lcssa-verification -lcssa -scalar-evolution -licm -postdomtree -adce -simplifycfg -domtree -basicaa -aa -loops -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -instcombine -barrier -elim-avail-extern -basiccg -rpo-functionattrs -globalopt -globaldce -basiccg -globals-aa -domtree -float2int -lower-constant-intrinsics -domtree -loops -loop-simplify -lcssa-verification -lcssa -basicaa -aa -scalar-evolution -loop-rotate -loop-accesses -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -loop-distribute -branch-prob -block-freq -scalar-evolution -basicaa -aa -loop-accesses -demanded-bits -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -loop-vectorize -loop-simplify -scalar-evolution -aa -loop-accesses -lazy-branch-prob -lazy-block-freq -loop-load-elim -basicaa -aa -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -instcombine -simplifycfg -domtree -loops -scalar-evolution -basicaa -aa -demanded-bits -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -slp-vectorizer -opt-remark-emitter -instcombine -loop-simplify -lcssa-verification -lcssa -scalar-evolution -loop-unroll -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -instcombine -memoryssa -loop-simplify -lcssa-verification -lcssa -scalar-evolution -licm -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -transform-warning -alignment-from-assumptions -strip-dead-prototypes -globaldce -constmerge -domtree -loops -branch-prob -block-freq -loop-simplify -lcssa-verification -lcssa -basicaa -aa -scalar-evolution -block-freq -loop-sink -lazy-branch-prob -lazy-block-freq -opt-remark-emitter -instsimplify -div-rem-pairs -simplifycfg -domtree -basicaa -aa -memoryssa -loops -loop-simplify -lcssa-verification -lcssa -scalar-evolution -licm -verify -print-module↩ -
As woodruffw commented on Hacker News, those LLVM registers are abstract and infinite. The real register allocation happens way later in the compilation pipeline. ↩